Solr ou l’élévation...des résultats
 Par
le 4
Décembre
2018
Par
le 4
Décembre
2018
Solr qui es-tu ?
Solr est un moteur de recherche. Il permet de stocker et indexer des données afin de permettre d’effectuer des recherches en mode « full text » ( c’est-à-dire que le moteur va essayer de faire correspondre chacun des mots d’un document indexé avec les mots de la recherche saisis par l’utilisateur). C’est ce moteur de recherche que nous utilisons sur decitre.fr, decitrepro.fr et nos marques blanches.
L’élévation pour quoi faire ?

Le principe de l’élévation, aussi connu sous le nom de « recherche sponsorisée », est lors d’une recherche sur un moteur tel que Google, ou dans notre cas Solr, de faire remonter en premier des résultats correspondants à la requête saisie par l’utilisateur.
Dans la majorité des cas, c’est une fonctionnalité qui se monnaye pour que les utilisateurs voient leur site ou produit remonter en tête de liste des résultats retournés, mais dans notre cas, le besoin premier est tout autre.
En effet, la pertinence paramétrée pour le classement des résultats est, à ce jour, principalement basée sur la notoriété ou potentielle notoriété de chacun des produits, notamment en terme de vente. Or dans le cas des produits à paraître, la pertinence se révèlera efficace seulement pour ceux dont la parution sera dans un délai assez court.
Nous avons donc la problématique de pouvoir proposer en tête de liste des résultats de recherche de produits que l’on sait importants mais qui paraîtront dans des mois.
Un autre cas de figure est de pouvoir remonter en tête de liste un produit ayant un rapport direct ou indirect avec la saisie ( par exemple faire remonter “les animaux fantastiques“ quand l’utilisateur saisit “harry potter”).
Génial Solr a un composant pour faire cela !
Et oui, Solr intègre en natif un composant ( QueryElevationComponent ) qui permet de faire cela, mais son fonctionnement est-il en adéquation avec l’utilisation souhaitée ?
La réponse est dans notre cas, non et ce, pour plusieurs raisons :
-
Il faut que nous puissions facilement limiter ces élévations dans le temps ou bien les programmer sur un intervalle de temps.
Or le fichier de configuration de l’élévation se présente comme cela :
<elevate>
<query text="foo bar">
<doc id="1" />
<doc id="2" />
<doc id="3" />
</query>
<query text="ipod">
<doc id="MA147LL/A" /> <!-- put the actual ipod at the top -->
<doc id="IW-02" exclude="true" /> <!-- exclude this cable -->
</query>
</elevate>
Comme on peut le voir, il n’y a aucune notion de date.
On indique seulement la requête qui doit être concordante avec la saisie utilisateur et la liste des ids des documents à élever ou bien à exclure si on ne veut pas que certains documents apparaissent sur certaines recherches.
-
Il faut aussi que la concordance entre la saisie utilisateur et les requêtes configurées pour l’élévation ne se limite pas à une recherche exacte. Et là encore, ça n’est pas vraiment le cas. En effet, si je paramètre une élévation avec comme termes “stephen king” par exemple et que l’utilisateur saisit ”christine stephen king”, cela ne concorde pas et l’élévation n’est pas faite. C’est même plus restrictif que cela, puisque si l’utilisateur saisit “king stephen”, cela ne correspondra pas plus.
-
Autre condition, il faut que cette fonctionnalité soit facilement paramétrable par l’équipe éditoriale. Et là on est clairement hors sujet. Le fichier de configuration des élévations est un fichier XML hébergé sur le serveur Solr dans le dossier du core correspondant. Autant dire un chemin semé d’embûches. Certes, on pourrait utiliser par exemple le plugin Solr elevate creator qui permet via les listeners du handler dataimport (DIH) de reconstruire le fichier à partir de données récupérées en base de données, mais cela ne résoudrait pas la totalité des points soulevés précédemment.
D’accord, alors comment fait-on ?
On a déjà à notre disposition, un back office permettant aux équipes éditoriales d’administrer les animations sur le site. On va donc s’appuyer dessus pour avoir une interface permettant de créer, modifier et supprimer des élévations qui seront stockées en base de données.
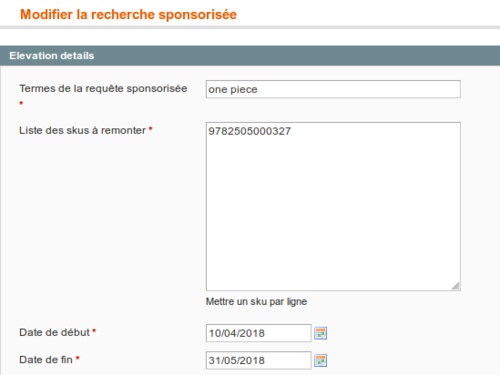
Cela nous permettra de pouvoir indiquer la requête à laquelle doit correspondre la saisie utilisateur, la liste des ids des produits à remonter ainsi qu’une date de début et de fin d’activation de l’élévation. Nous n’avons sciemment pas implémenté la liste d’exclusion car dans notre cas, on veut promouvoir. Toutefois, cela serait facile à ajouter.
Une fois les données en base, il va nous falloir un moyen de les injecter lors des recherches tout en évitant la contrainte de recherche exacte, voire de pouvoir tenir compte des éventuels synonymes que l’on souhaiterait gérer. Pour arriver à nos fins, on va créer un index Solr spécifique, cela permettra d’avoir une recherche full text avec laquelle nous pourrons ajouter des fonctionnalités comme la gestion des synonymes.
Le schéma des données de notre index sera très simple :
<field name="id" type="int" indexed="true" stored="true" />
<field name="query" type="text" indexed="true" stored="true" />
<field name="query_length" type="int" indexed="true" stored="true" />
<field name="skus" type="string" indexed="false" stored="true" />
<uniqueKey>id</uniqueKey>
Comme on peut le voir la liste des champs reflète ce que l’on a comme informations dans le back office à 2 exceptions près. Le query_length, que j’évoquerai après, et l’intervalle de date.
Les dates ne sont pas indexées car l’index sera toujours entièrement reconstruit et c’est donc seulement au moment de la requête SQL d’indexation que l’on prendra en compte les élévations dont la date d’indexation sera comprise dans l’intervalle comme on peut le voir dans la configuration du dataimport :
<document name="elevations">
<entity name="elevations" rootEntity="true"
query="
SELECT elevations.elevation_id AS id,
elevations.query AS query,
elevations.skus AS skus,
LENGTH(query) - LENGTH(REPLACE(query, ' ', '')) + 1 as query_length
FROM ${dataimporter.request.DB}.elevations as elevations
WHERE CURRENT_TIMESTAMP() BETWEEN start_date AND end_date
;"
>
</entity>
</document>
La configuration concernant notre index est faite, on peut maintenant indexer les données que nous avons saisies. Par la suite, il nous suffira d’ajouter une tâche d’indexation à la fréquence voulue pour maintenir notre index à jour.
Maintenant que l’on a notre index, il va falloir que notre handler de recherche principal puisse avoir accès à ces données et puisse élever les documents.
On va donc devoir créer notre propre composant à partir du composant QueryElevation de Solr.
En effet, le fonctionnement global du composant reste le même, seule la façon dont on récupère les informations correspondantes à la saisie utilisateur différera.
Donc au lieu de lire les données depuis le fichier XML, on va devoir à partir du core de recherche se connecter au core élévation, lancer une recherche avec les infos de l’utilisateur et récupérer la liste des skus des résultats correspondants.
La requête d’élévation sera faite sur l’index d’élévation via un handler spécifique configuré dans le solrconfig.xml de notre index d’élévation :
<requestHandler name="/elevate" class="solr.SearchHandler" startup="lazy">
<lst name="defaults">
<str name="echoParams">explicit</str>
<str name="q.op">OR</str>
<str name="qf">query</str>
<bool name="preferLocalShards">false</bool>
<str name="defType">edismax</str>
<str name="stopwords">false</str>
</lst>
<arr name="last-components">
<str>stopwords</str>
</arr>
</requestHandler>
C’est ce handler qui sera appelé par le composant QueryElevation. Il va donc falloir le passer en paramètre de ce composant défini au niveau de l’index principal de recherche :
<searchComponent name="elevator" class="com.decitre.solr.handler.component.QueryElevationComponent" >
<str name="coreName">IndexElevation_fr</str>
<str name="coreElevationHandlerName">/elevate</str>
<str name="queryFieldName">query</str>
<str name="idsFieldName">skus</str>
</searchComponent>
On va également, dans un souci de souplesse, pouvoir configurer le nom du core correspondant à l’index d’élévation, le champ utilisé pour appliquer la requête (queryFieldName), le nom du champ contenant la liste des ids des documents à élever (idsFieldName).
Ces paramètres vont être récupérés à l’initialisation du composant :
public void inform(SolrCore core)
{
... Some code ...
elevationCoreName = initArgs.get(CORE_NAME);
elevationHandlerName = initArgs.get(CORE_ELEVATION_HANDLER_NAME);
elevationIdsFieldName = initArgs.get(IDS_FIELD_NAME);
if (elevationIdsFieldName == null || elevationIdsFieldName.equals("") == true)
{
elevationIdsFieldName = "skus";
}
... Some code ...
}
Ensuite, on réécrit à sa guise la méthode getElevations issue du composant original qui gérait la récupération depuis le fichier XML afin de récupérer les élévations depuis l’index créé :
protected ElevationObj getElevations(String qstr, SolrParams params, ResponseBuilder rb) throws IOException {
CoreContainer container = rb.req.getCore().getCoreContainer();
final SolrCore elevationCore = container.getCore(elevationCoreName);
RefCounted<SolrIndexSearcher> searcherHolder = null;
if (elevationCore == null) {
log.error("Impossible de récupérer le core d'elevation : " + elevationCoreName);
return null;
}
SolrRequestHandler elevationRequestHandler = elevationCore.getRequestHandler(elevationHandlerName);
searcherHolder = elevationCore.getNewestSearcher(false);
SolrIndexSearcher searcher = searcherHolder.get();
QueryCommand currentCoreQueryCommand = rb.getQueryCommand();
if (elevationRequestHandler == null) {
log.error(String.format("Le handler %s n'existe pas dans la config du core %s", elevationRequestHandler, elevationCore.getName()));
return null;
}
// On définit ici les paramètres de la requête effectuée sur l’index
// d’élévation : query, nombre de documents à renvoyer, liste des
// champs à retourner
ModifiableSolrParams elevationParams = new ModifiableSolrParams();
elevationParams.set(CommonParams.Q, ext.escapeExtensionField(qstr));
elevationParams.set(CommonParams.FL, elevationIdsFieldName);
elevationParams.set(CommonParams.ROWS, NUMBER_OF_ELEVATION_SUGGESTIONS);
SolrQueryRequest queryRequest = new SolrQueryRequestBase(elevationCore, elevationParams) {};
SolrQueryResponse queryResponse = new SolrQueryResponse();
try
{
elevationRequestHandler.handleRequest(queryRequest, queryResponse);
} catch (Exception e) {
continue;
}
}
Et voilà moyennant encore quelques petites modifications, on a un composant fonctionnel.
Cool, on passe tout en test !
Tout va pour le mieux dans le meilleur des mondes !
Ça c’est ce que je me suis dit ! Mais dans les faits, il y avait un point que j’avais négligé.
En effet, pour que les saisies utilisateurs puissent correspondre avec les requêtes configurées, sur le handler d’élévation j’ai mis l’opérateur de requête (q.op) à OR. Cela signifie que dès qu’un mot de la recherche correspond à un des termes de requête de l’élévation, le document est retourné.
Par exemple dans mon back office j’ai configuré une élévation sur “harry”. L’utilisateur saisit “harry potter” dans la recherche. Les 2 harry correspondent, un seul me suffit, le document est retourné. Dans ce cas ça fonctionne.
Maintenant, j’ai configuré une élévation sur ”one piece” dans mon back office. L’utilisateur saisit “piece“ dans la recherche. Idem “piece” correspondant à un des termes, le document est retourné. Mais voilà, dans ce cas, je voulais seulement que les documents soient élevés quand tous les termes correspondent, sinon cela n’a pas vraiment de sens.
Alors vous me direz, facile, il y a juste à passer le q.op à AND, comme cela tous les termes devront correspondre. Oui c’est vrai, c’est même tellement vrai que ça en est trop restrictif.
Si on reprend notre exemple sur “one piece” il faudrait que l’utilisateur saisisse “one piece” pour que l’élévation soit retournée, en revanche, cela ne fonctionnerait pas en saisissant “one”, ce qui est attendu, mais également en saisissant “one piece manga”, ce qui est plus embêtant.
C’est donc à ce stade qu’intervient le champ query_length déclaré dans le schéma.
Comme on peut le voir dans la requête d’indexation, il va compter le nombre de termes de la requête en prenant <espace> comme séparateur (pour “one piece” le query_length vaudra 2).
Au moment de la recherche, dans notre composant, on va décomposer la saisie de l’utilisateur de la même façon qu’à l’indexation des élévations pour déterminer le query_length.
On va ensuite rechercher dans notre index d’élévation, la valeur maximum du query_length que nous avons entre 1 et le nombre de termes composant la requête utilisateur.
Donc, si dans notre index d’élévation on a :
| Termes élévation | query_length |
|---|---|
| titeuf | 1 |
| One piece | 2 |
Et que l’utilisateur saisit “one piece manga” (donc un query_length de 3), on récupèrera un max query_length de 2 qui est le max de notre index compris entre 1 et 3. On va ensuite faire des recherches itératives en partant de notre query_length maximum et en décrémentant jusqu’à 1.
Dans notre requête, on va modifier 2 éléments qui prendront la valeur de l’itération :
- Le filtre sur le query_length
- La valeur du minimum should match (mm) du parser de la requête
Cela va nous permettre de rechercher des documents dont le nombre de termes est inférieur ou égal au nombre de termes de la requête utilisateur tout en privilégiant ceux ayant le plus de termes en commun. Cela évitera également de trouver des résultats pour des requêtes utilisateur dont le nombre de termes est inférieur au nombre de termes de l’élévation. En reprenant notre exemple de l’index ci-dessus, si l’utilisateur saisit “one”, seuls les termes d’élévation de query_length à 1 seront recherchés. Donc “one piece” n’en fera pas partie et ne sera pas retourné.
Nous voilà arrivés au résultat escompté !
Le mot de la fin
A ce jour nous n’avons pas assez de recul pour avoir des métriques sur le potentiel impact positif d’une telle fonctionnalité.
Ce que l’on retient néanmoins c’est qu’elle va nous permettre de pouvoir facilement faire remonter des produits sur certains termes de recherches alimentés via notre back office pour des périodes données en lien direct ou contextuel avec la recherche de l’internaute.
Mais cela pourrait aussi, avec ce choix d’architecture, permettre l’alimentation de cet index d’une autre façon que via une base de données, Solr étant capable d’indexer des documents issus de diverses sources (fichiers texte, PDF, URL, …).
Certes tout n’est pas idéal, notamment la décomposition des saisies utilisateurs qui, uniquement faite sur les espaces, restreint le champ d’action, notamment dans le cas où la saisie comporte des apostrophes.
Mais nul doute que cette fonctionnalité évoluera au fil du temps !
Laisser un commentaire ?
Commentaire