Refonte de nos 3 millions de visuels produits - Les aventuriers du coffre perdu
 Par
le 12
Mars
2019
Par
le 12
Mars
2019
Cet article est le premier d’une série qui va parler de la refonte de nos visuels produits sur decitre.fr. Avant de parler des choix techniques que nous avons faits pour le format des images, les outils utilisés et comment nous les affichons, on va d’abord démarrer par la base : qu’affiche-t-on actuellement sur notre site et que va-t-on pouvoir faire de cette base de travail ?
État des lieux
Des visuels de mauvaise qualité
Vestige d’un choix technique fait il y a de nombreuses années, peut-être au début des années 2000 (voire 1990 ?), les visuels principaux de nos produits sont au format GIF.

En plus d’apporter d’interminables débats sur sa prononciation, le GIF est un format populaire car il permet d’être composé de plusieurs images dans un même fichier pour fournir une animation. Mais dans le cas de visuels produits, cette fonctionnalité d’image animée ne nous est pas très utile.
Côté qualité, ça n’est pas très positif : le format est limité à 256 couleurs choisies parmi les 16 millions de couleurs de la palette RVB. On se retrouve donc avec des visuels produits de qualité moyenne. Dur de donner envie d’acheter un livre avec ce genre d’image.




On pourrait se dire que c’est bien d’avoir des visuels de mauvaise qualité, qu’au moins en terme de performances web, on est bon car les fichiers sont légers.
Eh bien, non ! Malgré une faible quantité de couleur, on arrive à des poids d’images allant jusqu’à quelques dizaines de kilo-octets. Ce poids on pourrait facilement l’atteindre avec un format JPEG ou PNG sans travailler sur sa compression : on est donc perdant en qualité et poids.
Un point positif malgré tout, seul le visuel principal subit ce traitement (#historique). Les autres visuels (quatrième de couverture, extraits du livre, autres angles de vue du produit) nous sont envoyés aux formats PNG ou JPEG.
Le fonctionnement des images avant la refonte
Notre site est alimenté par notre ERP qui nous transmet régulièrement des visuels à afficher.
On reçoit deux types de visuels :
- les principaux, au format GIF et redimensionnés avec une taille n’excédant pas 500px de large,
- les secondaires dont le format n’est pas figé et qui ne subissent aucun traitement de redimensionnement.
Ces visuels sont ensuite retaillés à la demande et au besoin par Magento. Bien évidemment la version retaillée n’est faite qu’une fois, mais cette génération a un coût en terme de temps. Temps qui va être subi par l’utilisateur sur qui va tomber la génération.
Pire, on a parfois des pages qui atteignent la limite de mémoire PHP car on demande à notre Magento de retailler un visuel de 60Mo d’une image de 26000x26000 pixels et pour lequel, bizarrement, il a du mal à faire cette opération.
Notre infra, telle qu’elle est conçue actuellement, ne nous permet pas de générer lors l’intégration les différentes versions retaillées utilisées sur le site, ce qui aurait pu nous faire gagner en performance et éviter de faire subir ce coût de génération au premier utilisateur affichant l’image.
L’objectif de cette refonte
Voici donc ce que l’on souhaite obtenir dans le cadre de cette refonte :
- avoir des rendus de visuels plus qualitatifs en abandonnant le format GIF,
- générer en amont les visuels pour accélérer la génération côté serveur de nos pages webs,
- trouver un compromis acceptable entre le poids et la qualité des visuels générés,
- à terme, fournir des images adaptées pour les écrans à haute densité de pixels (Retina ou Super-AMOLED selon les marques).
On va pouvoir recevoir un nouveau flux venant de l’ERP, avec des visuels non altérés, c’est-à-dire qui n’ont subi aucune transformation de format ou de redimensionnement et dans un format d’origine (qui ne sera pas du GIF).
Pour les futures images, c’est une bonne nouvelle. Le problème, c’est l’historique.
20 ans de GIFs, ça se paye !
Decitre.fr existe depuis 1997, soit plus de 20 ans. Et en 20 ans, on en accumule des images. Entre le début du site et l’arrivée de ce fameux flux d’images non modifiées, nous avons 2.5 millions d’images au format GIF utilisées pour nos visuels principaux.
Vu qu’on revoit la qualité de nos visuels, ça serait dommage de ne pas s’occuper de ces 2.5 millions d’images pour que tout le site en profite.
Et c’est là que notre projet va connaître sa première difficulté : il n’y a pas d’historique officiel des images non modifiées depuis le début du site. Au pire, on a nos superbes GIFs comme base de travail, mais aucune trace du fichier à partir duquel ce GIF a été généré.
Heureusement, certains visuels peuvent être récupérés directement à partir de flux fournis par les éditeurs, d’autres peuvent être récupérés à partir des postes de notre équipe chargée de la numérisation des livres ou sur les serveurs de l’ERP.

Il va falloir chercher, à l’aide de ces différentes sources plutôt éparses, à reconstituer notre catalogue d’originaux.
À noter le point archéologie gagné par notre coffre-fort, où nous avons exhumé une centaine de DVDs et CDs pour les visuels d’avant 2007.

Point backup : les DVDs d’au moins 2004 sont toujours lisibles tandis que les CDs d’avant cette date sont inutilisables. Moralité, ça n’est pas tout de backuper, mais il faut également s’assurer que les contenus sauvegardés soient encore exploitables au fil du temps.
Le choix des candidats
Grâce à toutes ces sources, nous avons pu récupérer plus de 9 millions de visuels. Pour s’y retrouver, chaque image contient dans son nom l’EAN du produit auquel il fait référence.
On se retrouve donc avec plusieurs images candidates pour un même produit. Comment choisir l’image adéquate ? On va trier nos visuels en prenant en compte les critères suivants :
- la date de l’image,
- son poids,
- ses dimensions,
- l’endroit où l’image a été récupérée,
- son format.
L’objectif est de privilégier l’image la plus récente ayant la meilleure qualité possible. Ce tri nous permet de passer de 9 millions d’images à (seulement) 2 millions d’images après dédoublonnage.
Malheureusement, ces images ne sont pas toutes éligibles pour être directement utilisées sur le site. Parmi ces visuels, rien ne garantit qu’on en ait la dernière version, et on souhaite éviter de revenir à des contenus obsolètes par rapport aux GIFs actuellement en production.
Pour éviter cela, la prochaine étape va être de comparer 2 à 2 près de 5 millions d’image afin de prendre l’image candidate si elle est similaire au GIF ou bien le GIF si la différence entre les deux images est trop importante.
Trouver la meilleure image pour chaque produit
À raison de 2 millions et demi de comparaisons, si on compte 5s par comparaison, il va falloir 144 jours en continu (à peu près) à une seule personne pour y arriver, sans avoir aucune garantie que sa santé mentale ne soit pas altérée à la fin de ce processus.
On pouvait également envisager de passer par Amazon Mechanical Turk pour sous-traiter ces comparaisons. Mais le coût aurait été élevé.
Automatiser les comparaisons
Heureusement, on peut automatiser tout ça grâce à dssim, un outil de calcul de dissimilarité entre deux images.
Pour les plus pressés, on calcule un score de similarité (SSIM pour Structural SIMilarity) et dssim retourne une valeur 1/SSIM - 1. Plus la valeur est proche de 0, plus on peut considérer les visuels comparés comme étant identiques.
Pour les moins pressés, on trouve plus de littérature sur l’algorithme SSIM.
Pour ce calcul, notre choix s’est porté sur dssim. Un autre outil, Butteraugli, avait été envisagé, mais il était plus lent que dssim.
dssim va nous imposer plusieurs contraintes pour pouvoir fonctionner :
- les images doivent être au format PNG,
- les images doivent avoir les mêmes dimensions.
D’un côté, on va prendre le GIF utilisé en production, le convertir en PNG sans perte de compression. De l’autre, on prend notre image candidate, également convertie en PNG, puis on va la redimensionner aux dimensions du GIF.
Ensuite, on lance dssim pour obtenir notre score de similarité entre les deux images générées.
Le souci, c’est que le GIF a subi beaucoup d’altérations et que cela donne des scores DSSIM élevés alors que les images candidates peuvent être recevables.
Pour rattraper ces cas, on prépare un second calcul de score DSSIM en convertissant les deux images en niveau de gris. Cela permet dans certains cas de lisser les différences dues au passage à 256 couleurs du GIF et d’obtenir un score DSSIM acceptable.
Analyser les résultats des comparaisons
75h plus tard, nos 2.5 millions de comparaisons sont terminées et pour chaque couple d’images on a deux scores DSSIM sur lesquels il va falloir statuer.
Pour faire ce choix, nous avons considéré que tout score inférieur à 0.0015 était synonyme d’image similaire. Cette valeur a été choisie arbitrairement sur différents échantillons, où nous avons regardé à partir de quelles valeurs les images comparées étaient différentes.
On pose également quelques règles de décision automatiques peu importe le score (par exemple, on considère que certaines sources sont forcément les bonnes).
Cela nous laisse à peu près 20 000 images pour lesquelles nous n’avons pas pu prendre de décision.
Pour nous aider à analyser ce qui reste, nous nous sommes créés une interface affichant les deux images et les différentes propriétés puis, visuel après visuel, on indique lequel doit être conservé.
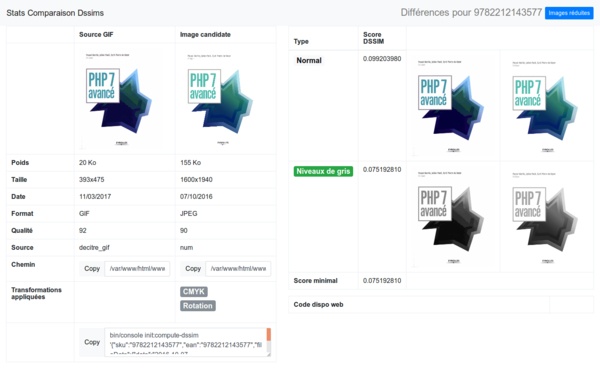
L’étape est légèrement fastidieuse, mais cela nous permet de préparer une base utilisant le plus possible des visuels qualitatifs à la place des GIFs.
Une quarantaine d’heures d’analyse plus tard, les choix restants ont été faits. Certaines règles automatiques ont été affinées, les images avec un score dssim proche du seuil fixé ont été traitées manuellement, et pour les autres nous avons conservé la version de production.
La suite au prochain épisode
La morale de toute cette première phase est la suivante : vu le coût du stockage aujourd’hui, la valeur de ce type de média et les nouveaux formats numériques à venir (dont on ne connaît pas encore l’existence), backupez proprement vos originaux :)
Malgré cela, toutes ces étapes de préparation nous ont permis de reconstituer notre historique d’une manière plutôt fiable. L’étape a été plutôt longue, le temps d’identifier et récupérer les différents contenus, enchaîner des journées de calculs, mais nous sommes désormais prêts à construire notre nouveau catalogue d’images produits, mais cela fera l’objet d’un prochain article.
Laisser un commentaire ?
Commentaire